0x1 Video Codec流程
视频编码流程如下图所示。
视频解码流程如下图所示。
如何对编解码器进行优化呢?
主要方法有算法优化,指令集优化和并行优化。本文的后面部分会对这些优化方法进行详细的介绍。
这边先来介绍一下优化的量化指标。
对编解码来说,共性的指标是编解码速度和消耗的功耗。编解码速度可以用fps来量化。这个是典型的软件优化过程,这个时候,诸如降低cache miss率,循环展开等优化思想都是适用的。
对软件编解码器而言,功耗可以量化为CPU占用率或者是MIPS(Million Instructions Per Second)。对硬件编解码器来说,功耗可以量化成硬件执行频率/硬件使用率等,也可以是硬件电压和电流参数。
对编码器来说,我们还需要保证相同码率下图像质量不衰退,这个衡量指标是PSNR和码率。在编码优化过程中,如何保证优化以后不出问题呢?我们知道编码的流程中是包括解码过程的,我们可以把编码过程中解码部分输出的YUV数据保存下来,再把编码生成的码流用参考解码器进行解码并保存为参考YUV输出,这个参考YUV输出和前面编码器中保存的YUV数据进行比较,如果两者的YUV数据有差异,可以确定是编码器优化出了问题,这个时候可以比较具体的比特位差异来快速定位问题。
另外在编解码优化过程中,我们还会用到码流分析工具,如Vega,streameye和yuvviewer等。
对解码器来说,我们还需要运行各种conformance test来保证解码优化以后不引入衰退。
0x2 算法优化
算法优化主要针对编码器而言的。
编码算法优化的目标有三个,一个是在保证质量的前提下降低码率,另一个是码率不变情况下提升编码质量。第三个目标是保证图形质量和码率不变的情况下提升编码速度。
前面两个的目标也是制定编解码器标准的目标,在一种特定的码流格式确定之前需要召开多次会议来讨论码流的细节,这种会议会讨论各个单位的提案,选出最佳的coding tools,达到最佳的压缩效率。下面我们来讨论一下如何按照第三个目标来优化编码器。
编码算法进行优化后,如何保证编码质量呢?这个时候需要通过客观指标如PSNR来保证,或者是类似的主观指标如MOS或者DMOS来保证。通过比较优化前后的PSNR,我们可以知道编码质量有没有下降。如何检查码率有没有变化呢?这个很简单,直接比较编码生成的文件大小有没有增加即可。
下面以AVC的编码器为例,看看如何对编码算法进行一定的优化。
帧内预测优化
比如在AVC的Luma帧内编码过程中,对应4x4大小的block,我们需要遍历9种预测方向来找到最优的预测方式。这个时候我们可以利用像素的特点减少预测方向的数量。另外还有16x16,8x8(High Profile而言)大小需要比较,这个时候都可以通过减少预测数量来优化。
帧间预测优化
对帧间预测的模式选择过程进行优化,因为运动估计比较耗时,如果所有模式都搜索一遍很耗时,可以利用像素特点对运动估计进行简化。
还有一种是I macroblock in P frame,需要计算什么情况下要在P frame采用Intra macroblock,这个过程也可以优化,对P frame中一个特定的宏块,可以采用某种方式来判断是否需要进行采用Intra编码,而不是需要计算好Inter和Intra的cost才能通过比较cost来选择。
另外可以采用不同的运动搜索算法来对简化通过运动搜索找到最佳运动矢量的过程。
码率控制优化
码率控制的过程是选择哪个宏块采用哪个量化参数QP的过程,有frame level的码率控制, 这个时候整个frame都是采用固定的QP。有slice level的码率控制,这个时候整个slice采用固定的QP。有macroblock level的码率控制,这个时候每个宏块可以自由地调节QP。macroblock level的码率控制是最准确的,但是计算复杂度也最大,可以通过在这几种码率控制级别之间进行选择,来达到码率控制和计算复杂度之间的平衡。
解码因为是固定的流程,算法没有办法进行优化,当然也有特例,如2006年左右PC性能比较差的时候,需要播放BluRay的AVC码流,在1080P情况下AVC软件解码性能不足,CPU占用率高,某播放器公司是把AVC的deblocking关闭的,当然画面质量会受到一些影响。另外在早期SOC平台性能不足,在软件解码的时候,很多时候会把不参与预测的B帧直接丢弃。
0x3 平台指令集优化
这种优化方法是采用各个平台特有的SIMD指令对编解码过程中某些运算过程进行加速,如x86上的mmx/sse/sse2/sse3/sse4/avx/avx512等SIMD指令,ARM平台上的SIMD指令有neon指令。
如编解码过程中典型的Hadmard变换,SATD, SAD, DCT, IDCT,运动补偿插值,Deblocking等过程都是很适合采用SIMD指令来加速的。
这里特别说明一下运动补偿插值的过程,目前AVC的Luma分量支持1/4像素的插值,也就是说每个像素需要插值成15个分像素点供后续运动估计使用。如果内存充足的话,可以利用SIMD方法把15个分像素点先计算好,这样在运动估计的时候就不需要做插值工作。
如下图所示,方框所示为整像素点,圆形所示为分像素点。可以按照1/2/3, 4/8/12, 5/7/13/15, 10, 6/9/11/14的过程进行SIMD计算。![]()
目前各个开源编解码库,如ffmpeg,x264,xvid,x265等,这些库的很大部分优化工作就是在各个平台上进行SIMD优化。
0x4 GPU并行优化
这里说的GPU并行优化一般指采用opencl/cuda之类的GPU Compute API来进行编解码的处理。
x264中采用了opencl来进行编码优化,把CPU需要完成的工作offload到GPU中来完成,其中x264采用opencl来在analysis阶段分析像素的特点来提前确定GOP中IBP帧的排列分布,还用来判断当前Slice是需要用Intra编码还是Inter编码。
0x5 并行优化
0x51 分布式优化
分布式优化一般用于编码优化,基本原理是把需要编码的文件划分成几个部分,每一部分分别在不同的机器上进行编码,编码完成以后再把编码好的几段码流合并成一个完整的码流。这种编码优化方法一般多见于专业视频制作过程,需要保证图形质量最佳的情况下码率最小,一般会启用编码器中的所有feature。另外一般采用多pass的编码方法,第一个pass先分析输入素材的特点,根据分布式处理的机器数目来确定那一段输入素材在哪台机器上进行编码。另外需要指出的是在分割点附近的码率控制算法需要特别处理,否则容易出现码率突然增大的情况。
0x52 GOP并行优化
这种优化方法是把一个GOP分配给一个线程来进行优化。
对编码而言,可以控制每个GOP中frame的数目,并且不采用Open GOP,只采用Close GOP的方式来进行编码。这样每个线程的负载可以做到比较平均。每个GOP开头和结尾处的码率控制需要特别处理。
对解码而言, 如果GOP之间的frame数目差别较大,则没有办法做到线程的负载平衡。而且如果是Open GOP的话,线程之间也有等待操作。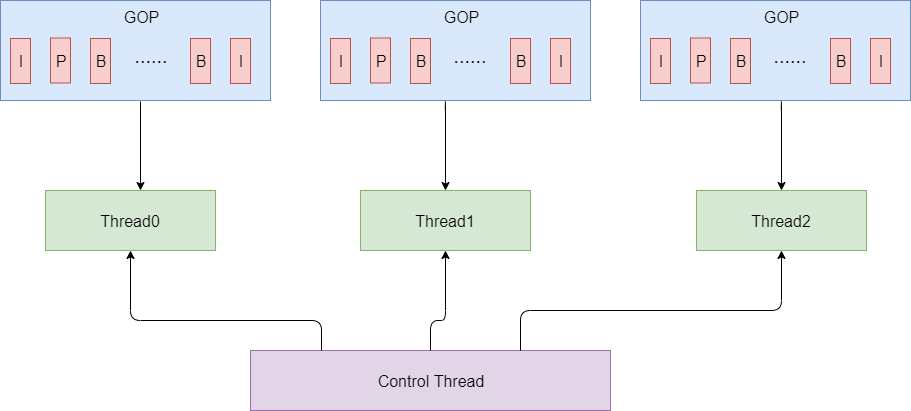
0x53 Frame并行优化
Frame级别优化是把Frame分配给不同的线程处理,一般用于视频解码,如果当前帧的当前宏块的解码过程需要依赖于前面帧的解码完成,这个时候是需要等待,这个在目前的视频标准中是很常见的。如P帧的解码需要依赖前面I帧的解码完成。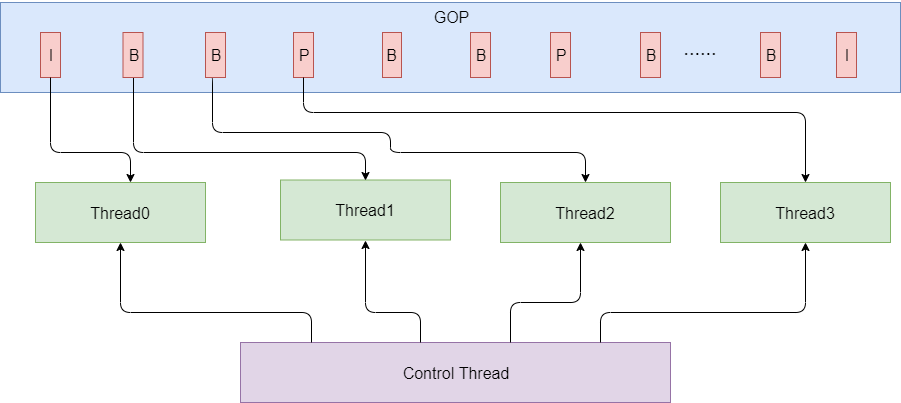
0x54 Slice并行优化
对编码器来说,可以按照多个Slice来并行编码,只需要在编码器启动的时候配置好Slice数目即可,需要注意的是,Slice编码完成以后,一般需要进行Deblocking,这个过程是跨Slice边界的,也就是说这个时候没有办法并行处理了,需要等待所有Slice编码完成以后在Control Thread中完成Deblocking的过程。
对解码器来说,按照码流中的slice数目启动多线程解码。
这种并行优化方式的优点是实现简单。
这种并行优化方式的缺点是,对编码器来说会稍微损失码率,对解码器来说是依赖于slice数目,如果只有一个slice,没办法并行处理。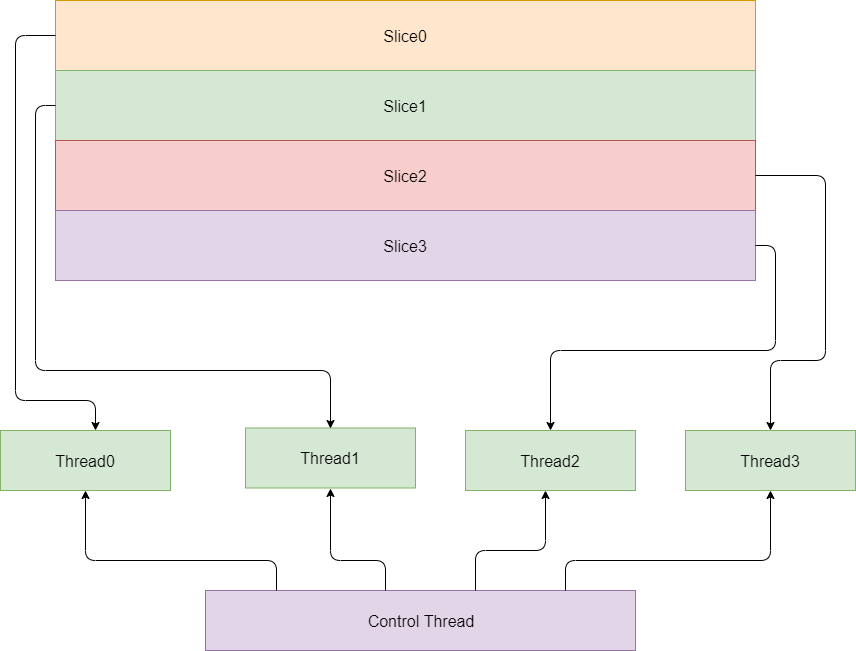
0x55 MB Block并行优化
这种优化方式一般用于解码器。优点是线程负载比较平衡,缺点是实现较复杂,需要深入解码器内部进行划分任务,把解码任务划分成不同的阶段,如VLD,IDCT,MC,Deblocking等。每个线程只是执行一个阶段的任务,而且执行的宏块数也只是上图中一个长方框内的宏块数目。这个时候如果算法的实现中对前后方框之间的宏块有数据依赖的话,需要加入同步机制。如ffmpeg就没有实现这种方式。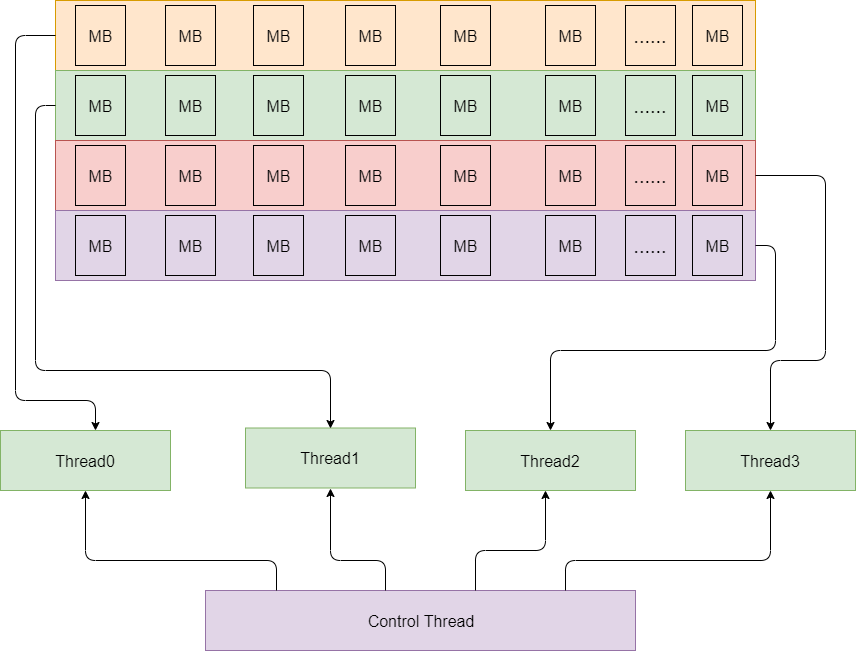
0x6 AI优化
AV1的参考编码器libaom中采用了AI来加速partiton划分, partiton划分在libaom中占用了大概80%的复杂度。libaom编码过程中采用的CNN + DNN的网络是经过训练的,在libaom的代码中并没有提供这个网络结构的训练过程代码。但是从其推理过程我们可以大体知道其训练过程,其实现方式应该是设计好网络以后,通过大量样本数据来训练得到该推理网络的。
0x7 硬件优化
下面提到的DXVA和LibVA是指通过GPU集成的视频编解码能力来加速视频处理。
DXVA指Windows平台上的GPU视频编解码加速标准。
LibVA指Linux平台上的GPU视频编解码加速标准。
DXVA架构图如下所示。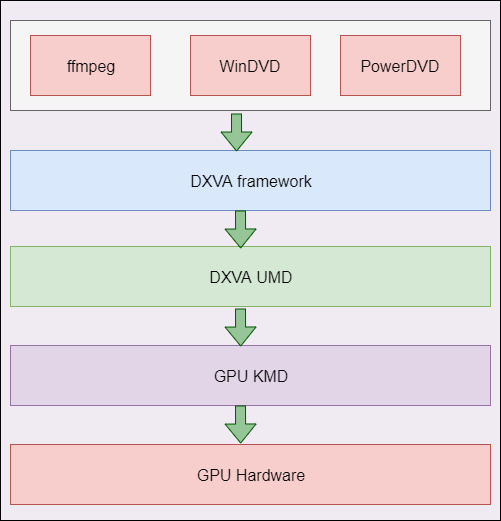
LibVA架构图如下所示。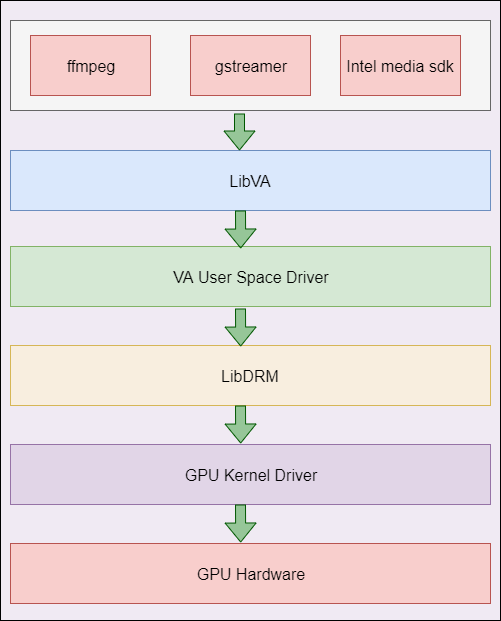
ASIC优化
还有一种优化方法是把编解码模块做成ASIC模块,如早期的WisChip公司的视频编解码器。
现在Verisilicon公司的Hantro IP, Broadcom的VideoCore, 各个手机SOC厂商(Huawei, MTK, Spreadtrum, qualcomm)在SOC中集成的视频编解码IP。
DSP优化
如TI公司的DSP平台如TMS320C64可以用来优化Codec。
FPGA优化
如Altera和Xilinx的FPGA都可以用来优化视频编解码能力。
0x8 优化思考
目前openmp, tbb等基础库已经很成熟,已经广泛应用于各种深度学习推理框架的优化中。视频编解码优化应该也可以采用这些基础库来优化。
另外是可以思考是否可以采用TVM类似框架来优化,现在对推理框架的优化热潮和十多年前对codec的优化热潮很像。如果可以有TVM类似的框架,目前视频编解码优化中各种平台上的手写SIMD优化工作应该可以通过类似的AutoTune工作来完成。这样视频编解码优化的工作可以从繁重的手写汇编的工作中解放出来,把优化侧重点放在对算法和计算流程方面的优化。